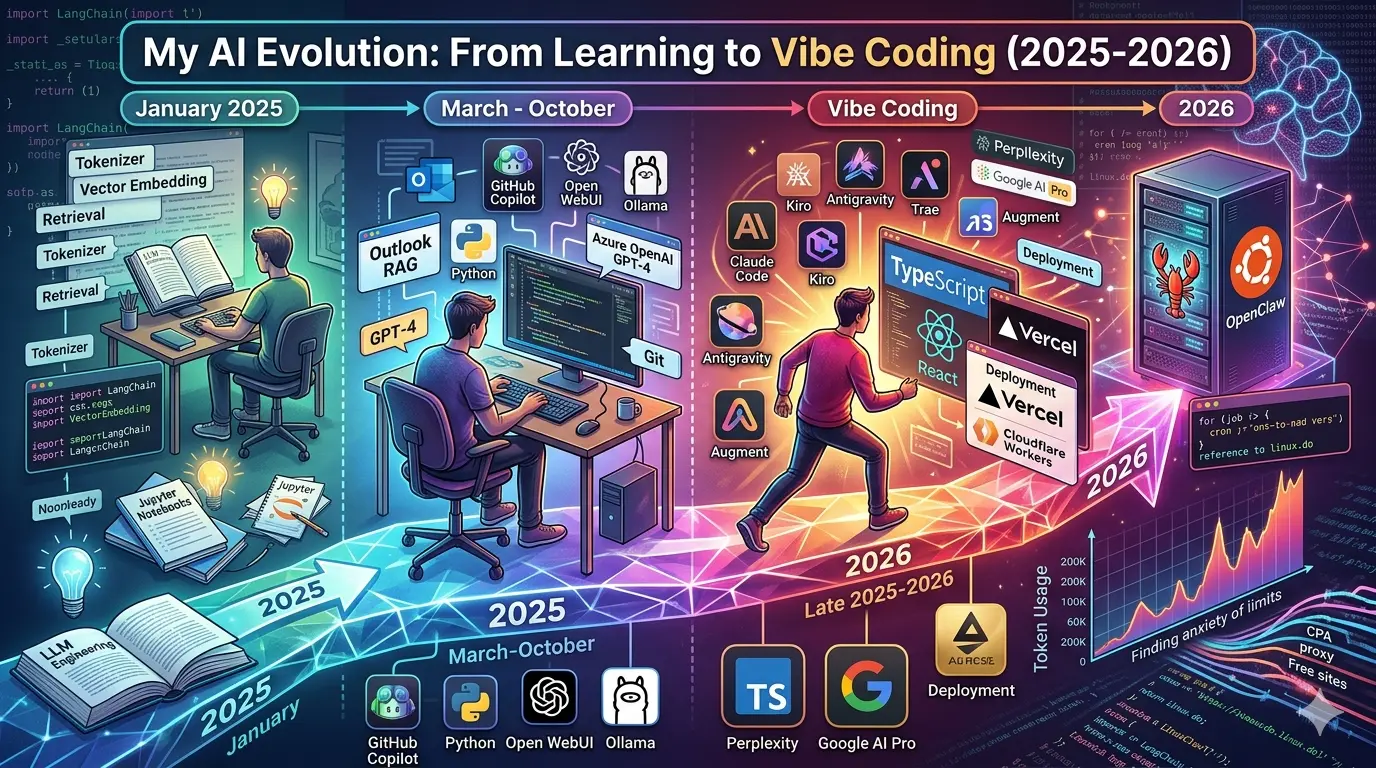
如果不把 ChatGPT 这类现成的 chatbox 应用算进去,我真正开始系统接触 AI,是从 2025 年 1 月开始的。那时候我开始理解 LLM,重新碰 Python,也开始用 Jupyter Notebook 去写一些最基础的实验和记录。
2025 年 1 月
现在回头看,那很像一个真正的起点。因为从那时开始,我和 AI 的关系不再只是偶尔聊几句、问几个问题,而是真的开始自己动手写代码、跑流程、试模型。
我是从 Udemy 上 Ed Donner 的课程《LLM Engineering: Master AI and Large Language Models & Agents》开始的,配套代码主要就是 GitHub 上的 llm_engineering 仓库。也是在那段时间里,我第一次系统接触 tokenizer、vector embedding、retrieval、文本切分这些概念,也开始用 Jupyter 跑一些简单的 AI 小实验。
现在看,这一步已经很基础了,但它确实很关键。因为后面不管是模型调用、知识库、向量检索,还是 AI 编程助手,基本都是从这里一点点长出来的。
2025年3~6月
2025 年春节过后,随着我对 LLM 开始有了一点真正的理解,我动手做了自己的第一个 AI 项目:想把 Outlook 邮箱做成一个个人知识库。
现在回头看,这个想法其实很自然。邮件本来就是我积累了很多年的信息库,如果能把它们抽出来,再经过切分、tokenizer、embedding 和 retrieval,理论上就可以变成一个能够查询和对话的 RAG 系统。
那时我还几乎完全处在手工 coding 的阶段,主要靠 VS Code 和 Jupyter 插件一点点调试,不像现在很多事情已经可以交给 vibe coding 去完成。也正是在这个阶段,我开始真正用 Python 和 LangChain 来做项目,把原来在课程里接触到的概念一点点变成代码和流程。 模型方面,我当时主要使用的是 Azure OpenAI 的 GPT-4。
项目最后确实跑通了,但并没有达到我期待中的实用程度。到现在我也说不清问题究竟出在哪,可能和我近 20 年的邮件总量有关,也可能是检索、分块或者数据清洗这些环节当时还做得不够好。
不过这个项目依然非常关键。因为很多后来我觉得已经很自然的东西,比如 Git、Chroma、Tkinter,以及“怎么把一个 AI 想法真正做成项目”这件事,基本都是从这里开始的。
2025年7~10月
随着之前个人知识库的尝试,我开始注意到越来越多现成的 AI 应用入口,比如 LM Studio、Cherry Studio 和 Open WebUI。那时候我已经不再满足于只在 notebook 里做实验,而是开始想找一种更稳定、也更接近日常使用的方式,把模型真正接进自己的环境里。
几种工具试下来,我最后选择了 Open WebUI,并且一直沿用到了现在。它本身就是一个支持 Ollama 和 OpenAI 兼容 API 的自托管 AI 界面,这对当时的我来说很合适:既能继续保留本地和自建的感觉,又不用每次都从脚本或者命令行重新开始。
也是在折腾 Open WebUI 配置的过程中,我开始接触和 AI 相关的更多服务和能力,比如 web search、图像处理、文件识别,以及不同模型和不同接口之间的连接方式。回头看,这一阶段对我的意义,不只是多装了几个工具,而是让我开始从“LLM 基础知识”往更完整的 AI 使用体验走,慢慢接触到多模态、token、上下文长度这些更贴近实际使用的问题。
也是差不多从这个时候开始,我第一次真正接触到后来被叫作 vibe coding 的东西。最早进入我视野的应该是 GitHub Copilot。再往后,VS Code 里的这类工具越来越多,比如 Cline、Roo Code、Augment。GitHub Copilot 很自然地成了我从“手工 coding”为主,慢慢过渡到“AI 参与编码”的起点。
2025年底
到了 2025 年底,AI 编程这件事的热度明显又上了一个台阶。前面一段时间里,国外比较流行的主流 AI IDE 主要还是 Windsurf 和 Cursor,不过我自己其实并没有太深入地用它们。真正让我开始大规模进入 vibe coding 状态的,反而是后来这一批工具:国外有 Claude Code、Kiro、Antigravity,国内也开始出现 Trae、CodeBuddy 这一类产品。
我自己的使用也是从这时候开始真正放大的。最早主要还是用 Augment 这类 VS Code 插件,后来慢慢转向 Kiro 和 Antigravity。模型方面,一开始更多用的是 Claude Code 和 Opus 4.0,Kiro 那时还能免费试用这个模型。再往后,逐渐变成了 VS Code + Codex,再加上 Antigravity 这样的组合。
vibe coding 最大的变化,是它让我以前很多停留在脑子里的想法,第一次有机会快速落地。以前我用 Excel 表格管理的一些东西,后来真的被我一点点做成了 TypeScript + React 的小应用,并部署到了 Vercel 上。也就是在那几个月里,Vercel、Cloudflare Workers、TypeScript、React、Neon、Context7 这些东西几乎被我密集地摸了一遍,而且很多时候免费账号就已经够用了。
也是在这一段时间,我开始更认真地把这些工具当成长期工作流的一部分,而不是偶尔试试的新玩具。为了配合使用,我那时候还注册了 Perplexity 和 Google AI 的 Pro 会员。现在回头看,这一段很像是我从“会用一些 AI 工具”,正式走到“开始依赖 AI 搭项目、做原型、验证想法”的阶段。
2026年2~4月
到了 2026 年 2 月到 4 月,随着 vibe coding 越用越频繁,我对 token 的消耗也开始迅速上升。偏偏这时候,之前的一些试用会员和 Google 的额度又被明显削减,很多原本还能比较随意用的东西,一下子就变得紧张起来。
这种变化对使用体验影响很大。Antigravity 经常没用多久就碰到限制,Azure OpenAI 那边很多时候也只能退回去用 gpt-5.1-codex。吃惯了前面那些更顺手、更“细粮”的模型以后,再回头用这些相对朴素的配置,心理落差其实挺明显的。
也是在这段时间,一个注册了一年多的网站 linux.do 被我刷得越来越勤。为了想办法把手头这些工具继续用起来,我开始频繁接触 CPA、反代、公益站这些原本并不在我主线里的东西。现在回头想,这段经历多少有点荒诞,但也确实很符合那时候的状态:一边焦虑额度,一边想尽办法继续把整个工作流维持下去。
另外2026春节过后,openclaw 这只“小龙虾”又突然流行起来。我也跟风在家里的 Ubuntu 服务器上养了一只。它是个典型的 token 消耗大户,而我当时真正负担得起的模型,基本只剩下 Azure OpenAI 的 gpt-5.4-mini。为了把它调通,我花了不少时间,但真正能落地的使用场景其实并不多。到现在,它更多还是停留在发 cron 提醒、回答一些小问题的阶段,实用性甚至还不如豆包。
现在先记到这里
这篇文章不会是终稿。
AI 变化得很快,我自己的使用方式也一直在变。今天觉得只是试试看的一项工具,过几个月可能会变成主力;今天很常用的一种方法,也可能在之后慢慢被替换掉。所以这篇文章对我来说,更像一个持续更新的日志入口。
先把这一段路记下来。以后继续往后写。


Time flies
昨天cursor扣费,忽然有点懵,我才发现用了也一年了。